Przewodnik dla początkujących dotyczący synchronizowania danych z Rsync
Protokół rsync może być dość prosty w użyciu do zwykłych zadań tworzenia kopii zapasowych / synchronizacji, ale niektóre z jego bardziej zaawansowanych funkcji mogą Cię zaskoczyć. W tym artykule pokażemy, że nawet najwięksi hakerzy danych i entuzjaści tworzenia kopii zapasowych mogą używać rsync jako jednego rozwiązania dla wszystkich potrzeb związanych z redundancją danych.
Ostrzeżenie: tylko zaawansowani geekowie
Jeśli siedzisz i myślisz "Co do cholery jest rsync?" Lub "Używam tylko rsync do naprawdę prostych zadań", możesz sprawdzić nasz poprzedni artykuł na temat używania rsync do tworzenia kopii zapasowych danych w systemie Linux, co daje wprowadzenie do rsync, prowadzi cię przez instalację i prezentuje jej bardziej podstawowe funkcje. Kiedy już będziesz miał pewną wiedzę na temat używania rsync (szczerze mówiąc, nie jest to aż tak skomplikowane) i czujesz się komfortowo z terminalem linuksowym, możesz przejść do tego zaawansowanego przewodnika.
Uruchamianie rsync w systemie Windows
Najpierw pobierzmy nasze czytniki Windows na tej samej stronie co nasi guru Linux. Mimo że rsync jest zbudowany tak, by działał na systemach uniksopodobnych, nie ma powodu, aby nie był w stanie używać go równie łatwo w systemie Windows. Cygwin tworzy wspaniały Linux API, którego możemy używać do uruchamiania rsync, więc przejdź do ich strony internetowej i pobierz wersję 32-bitową lub 64-bitową, w zależności od komputera.
Instalacja jest prosta; możesz zachować wszystkie opcje w ich domyślnych wartościach, aż dojdziesz do ekranu "Wybierz paczki".
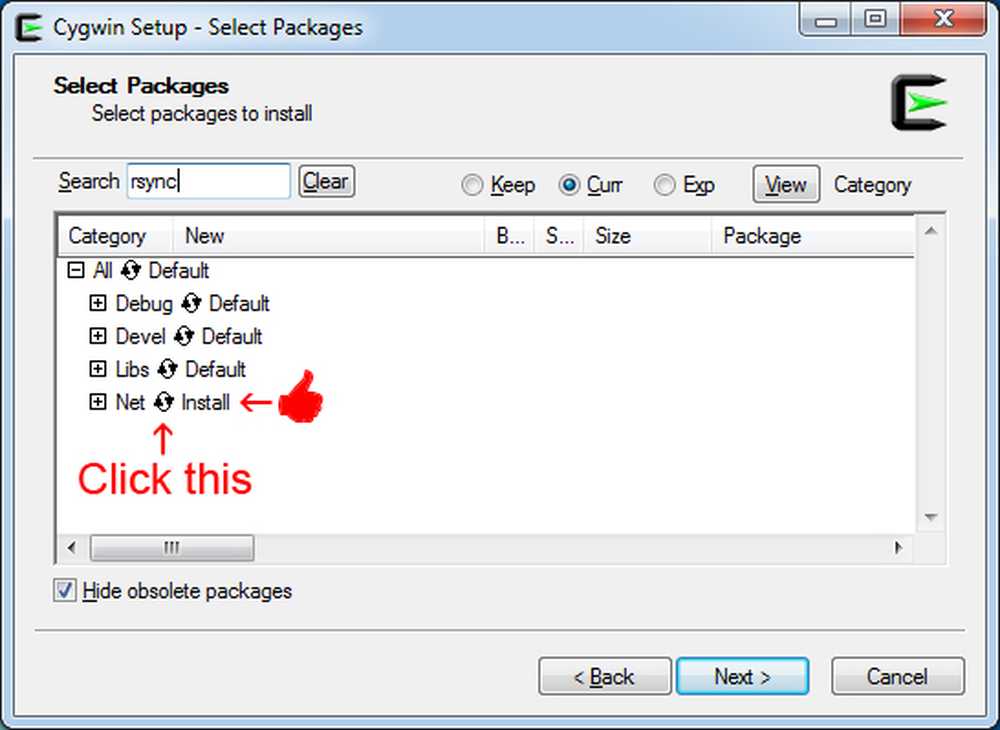
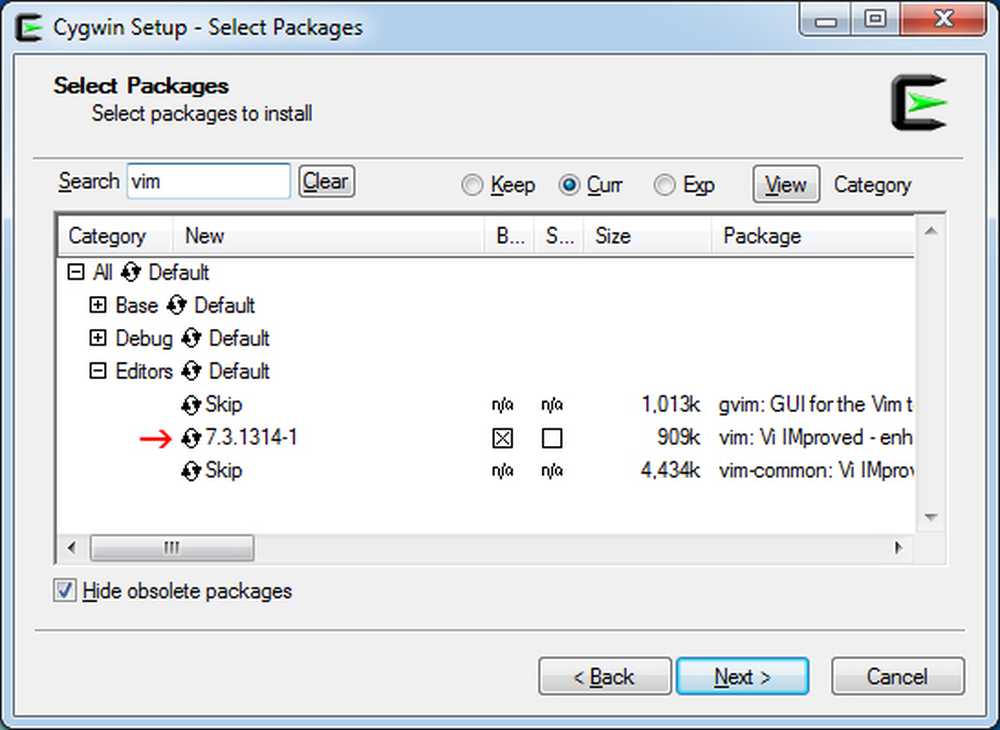
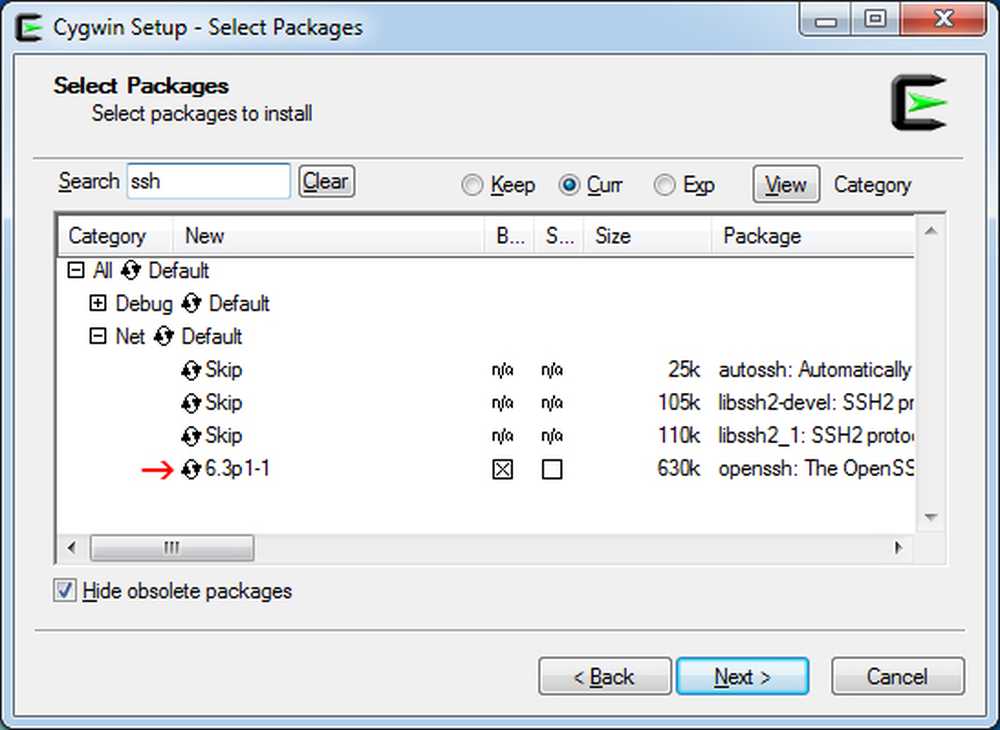
Teraz musisz wykonać te same kroki dla Vima i SSH, ale pakiety będą wyglądać nieco inaczej, gdy wybierzesz je, więc oto kilka zrzutów ekranu:
Instalowanie Vima:
Instalowanie SSH:
Po wybraniu tych trzech pakietów klikaj dalej, aż do zakończenia instalacji. Następnie możesz otworzyć Cygwin klikając ikonę, którą instalator umieścił na twoim pulpicie.
Polecenia rsync: od Simple do Advanced
Teraz, gdy użytkownicy Windowsa znajdują się na tej samej stronie, rzućmy okiem na prostą komendę rsync i pokażmy, jak użycie niektórych zaawansowanych przełączników może szybko uczynić ją złożoną.
Załóżmy, że masz kilka plików, które wymagają kopii zapasowej - kto nie ma tych dni? Podłączasz przenośny dysk twardy, abyś mógł tworzyć kopie zapasowe plików komputerów i wydał następujące polecenie:
rsync -a / home / geek / files / / mnt / usb / files /
Lub sposób, w jaki wyglądałby na komputerze z systemem Windows z Cygwin:
rsync -a / cygdrive / c / files / / cygdrive / e / files /
Całkiem proste i w tym momencie naprawdę nie ma potrzeby używania rsync, ponieważ można po prostu przeciągać i upuszczać pliki. Jeśli jednak na drugim dysku twardym znajdują się już niektóre pliki i potrzebne są tylko zaktualizowane wersje oraz pliki utworzone od czasu ostatniej synchronizacji, to polecenie jest przydatne, ponieważ przesyła nowe dane tylko na dysk twardy. Duże pliki, a zwłaszcza przesyłanie plików przez Internet, to wielka sprawa.
Tworzenie kopii zapasowych plików na zewnętrznym dysku twardym, a następnie przechowywanie dysku twardego w tym samym miejscu, co komputer, jest bardzo złym pomysłem, przyjrzyjmy się więc, co będzie konieczne, aby rozpocząć wysyłanie plików przez Internet do innego komputera ( jeden, który wypożyczyłeś, członek rodziny itd.).
rsync -av --delete -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files /
Powyższe polecenie spowoduje wysłanie plików na inny komputer z adresem IP 10.1.1.1. Usunąłoby to zbędne pliki z miejsca docelowego, które już nie istnieją w katalogu źródłowym, wyprowadza przesyłane nazwy plików, dzięki czemu masz pojęcie o tym, co się dzieje, i tunelowanie rsync przez SSH na porcie 12345.
The -a -v -e --delete przełączniki są jednymi z najbardziej podstawowych i najczęściej używanych; powinieneś już wiedzieć dużo na ich temat, jeśli czytasz ten samouczek. Przeanalizujmy inne przełączniki, które czasami są ignorowane, ale niezwykle przydatne:
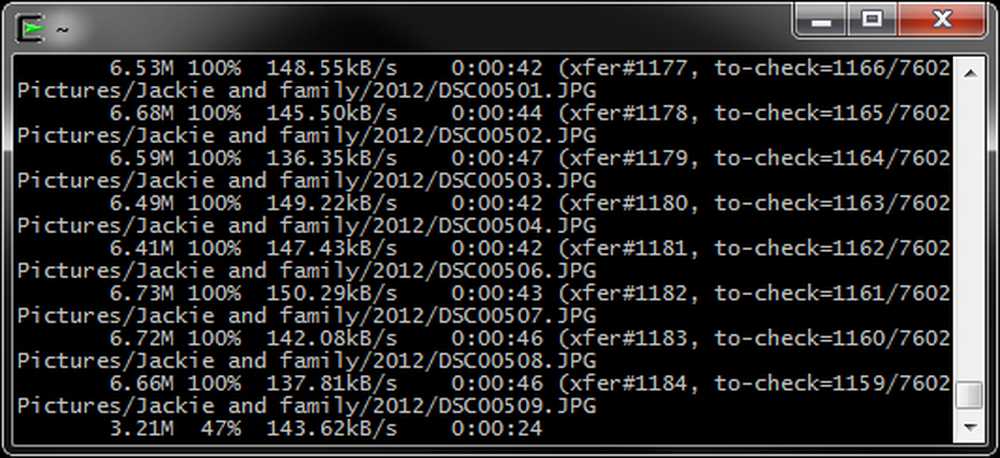
--postęp - Ten przełącznik pozwala nam zobaczyć postęp transferu każdego pliku. Jest to szczególnie przydatne podczas przesyłania dużych plików przez Internet, ale może generować niepotrzebną ilość informacji podczas przesyłania małych plików przez szybką sieć.
Polecenie rsync z --postęp przełącz się, gdy trwa tworzenie kopii zapasowej:
--częściowy - Jest to kolejny przełącznik, który jest szczególnie przydatny podczas przesyłania dużych plików przez Internet. Jeśli rsync zostanie przerwany z dowolnego powodu w trakcie przesyłania pliku, częściowo przesłany plik zostanie zachowany w katalogu docelowym, a transfer zostanie wznowiony tam, gdzie został przerwany po ponownym uruchomieniu polecenia rsync. Przesyłając duże pliki przez Internet (na przykład kilka gigabajtów), nie ma nic gorszego niż kilka sekund przerwy w Internecie, niebieski ekran lub błąd człowieka podczas transferu plików i konieczności rozpoczynania od nowa..
-P - ten przełącznik łączy --postęp i --częściowy, więc użyj go zamiast tego, a to sprawi, że twoja komenda rsync będzie trochę ładniejsza.
-z lub --kompres - Ten przełącznik sprawi, że rsync skompresuje dane pliku podczas przesyłania, zmniejszając ilość danych, które należy przesłać do miejsca docelowego. W rzeczywistości jest to dość powszechny przełącznik, ale nie jest to istotne, tylko przynosi korzyści w przypadku transferów między wolnymi połączeniami i nie ma wpływu na następujące typy plików: 7z, avi, bz2, deb, g, z izo, jpeg, jpg, mov, mp3, mp4, ogg, rpm, tbz, tgz, z, zip.
-h lub --czytelne dla człowieka - Jeśli używasz --postęp przełącznik, zdecydowanie zechcesz także użyć tego. Oznacza to, że jeśli nie chcesz konwertować bajtów do megabajtów w locie. The -h switch konwertuje wszystkie wyprowadzane liczby na format czytelny dla człowieka, dzięki czemu można właściwie określić ilość przesyłanych danych.
-n lub --próba - Ten przełącznik jest niezbędny, aby wiedzieć, kiedy po raz pierwszy piszesz skrypt rsync i testujesz go. Wykonuje test próbny, ale w rzeczywistości nie wprowadza żadnych zmian - przyszłe zmiany są nadal wysyłane w normalny sposób, więc możesz przeczytać wszystko i upewnić się, że wszystko wygląda dobrze przed przeniesieniem skryptu do produkcji.
-R lub --krewny - Tego przełącznika należy użyć, jeśli katalog docelowy jeszcze nie istnieje. Użyjemy tej opcji w dalszej części tego przewodnika, abyśmy mogli tworzyć katalogi na maszynie docelowej z sygnaturami czasowymi w nazwach folderów.
--Wykluczyć z - Ten przełącznik służy do łączenia z listą wykluczeń, która zawiera ścieżki do katalogów, których nie chcesz zarchiwizować. Potrzebny jest jedynie zwykły plik tekstowy z katalogiem lub ścieżką do pliku w każdej linii.
--include-from - Podobny do --Wykluczyć z, ale łączy się z plikiem, który zawiera katalogi i ścieżki plików danych, które chcesz zarchiwizować.
--statystyki - W rzeczywistości nie jest to ważny przełącznik, ale jeśli jesteś administratorem, przydatna może być znajomość szczegółowych statystyk każdej kopii zapasowej, dzięki czemu możesz monitorować natężenie ruchu przesyłanego przez sieć i takie dane..
--plik dziennika - Umożliwia to wysyłanie danych wyjściowych polecenia rsync do pliku dziennika. Zdecydowanie zalecamy to w przypadku zautomatyzowanych kopii zapasowych, w których nie można samemu odczytać danych wyjściowych. Zawsze dawaj pliki dziennika raz w swoim wolnym czasie, aby upewnić się, że wszystko działa poprawnie. Co więcej, jest to kluczowy przełącznik, z którego powinien korzystać sysadmin, więc nie zastanawiasz się, w jaki sposób twoje kopie zapasowe zawiodły, gdy opuściłeś stażystę odpowiedzialnego za.
Rzućmy okiem na naszą komendę rsync po dodaniu kilku dodatkowych przełączników:
rsync -avzhP --delete --stats --log-file = / home / geek / rsynclogs / backup.log --exclude-from '/home/geek/exclude.txt' -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files /
Polecenie jest nadal dość proste, ale wciąż nie stworzyliśmy przyzwoitego rozwiązania do tworzenia kopii zapasowych. Mimo że nasze pliki znajdują się teraz w dwóch różnych fizycznych lokalizacjach, ta kopia zapasowa nie robi nic, aby uchronić nas przed jedną z głównych przyczyn utraty danych: ludzki błąd.
Kopie migawkowe
Jeśli przypadkowo usuniesz plik, wirus uszkodzi wszystkie pliki lub wystąpi coś innego, co spowoduje niepożądaną zmianę plików, a następnie uruchomisz skrypt rsync backup, dane z kopii zapasowej zostaną zastąpione niepożądanymi zmianami. Kiedy coś takiego występuje (nie wtedy, ale kiedy), rozwiązanie do tworzenia kopii zapasowych nie zrobiło nic, aby uchronić Cię przed utratą danych.
Twórca rsync zdał sobie z tego sprawę i dodał --utworzyć kopię zapasową i --backup-dir argumenty, aby użytkownicy mogli uruchamiać różnicowe kopie zapasowe. Pierwszy przykład na stronie rsync pokazuje skrypt, w którym pełna kopia zapasowa jest uruchamiana co siedem dni, a następnie zmiany w tych plikach są zapisywane w oddzielnych katalogach codziennie. Problem z tą metodą polega na tym, że aby odzyskać swoje pliki, musisz je skutecznie odzyskać siedem razy. Co więcej, większość maniaków uruchamia swoje kopie zapasowe kilka razy dziennie, więc z łatwością możesz mieć ponad 20 różnych katalogów kopii zapasowych w dowolnym momencie. Nie tylko odzyskiwanie plików jest teraz uciążliwe, ale nawet samo przeglądanie kopii zapasowej danych może być bardzo czasochłonne - musisz znać ostatni raz, kiedy plik został zmieniony, aby znaleźć jego ostatnią kopię zapasową. Co więcej, nieefektywne jest uruchamianie tylko raz w tygodniu (lub nawet rzadziej) przyrostowych kopii zapasowych.
Tworzenie kopii zapasowych Snapshot na ratunek! Kopie migawkowe to nic innego jak przyrostowe kopie zapasowe, ale wykorzystują twarde linki do zachowania struktury plików oryginalnego źródła. Na początku może być trudno owinąć głowę, więc spójrzmy na przykład.
Udawaj, że mamy uruchomiony skrypt kopii zapasowej, który co dwie godziny automatycznie tworzy kopie zapasowe danych. Ilekroć rsync robi to, nazywa każdą kopię zapasową w formacie: Backup-month-day-year-time.
Tak więc, na koniec typowego dnia, będziemy mieli listę folderów w naszym katalogu docelowym w następujący sposób:

Przechodząc przez którykolwiek z tych katalogów, zobaczysz każdy plik z katalogu źródłowego dokładnie tak, jak był w tym czasie. W żadnym z dwóch katalogów nie byłoby jednak duplikatów. rsync realizuje to za pomocą hardlinkowania poprzez --link-dest = DIR argument.
Oczywiście, aby mieć te ładnie i starannie spisane nazwy katalogów, będziemy musieli nieco poprawić nasz skrypt rsync. Rzućmy okiem na to, co trzeba zrobić, aby wykonać takie rozwiązanie do tworzenia kopii zapasowych, a następnie wyjaśnimy ten skrypt bardziej szczegółowo:
#! / bin / bash
#copy old time.txt do time2.txt
tak | cp ~ / backup / time.txt ~ / backup / time2.txt
#overwrite stary plik time.txt z nowym czasem
echo "date +"% F-% I% p ""> ~ / backup / time.txt
#wybierz plik dziennika
echo ""> ~ / backup / rsync-wouldate + "% F-% I% p" 'log
Polecenie #rsync
rsync -avzhPR --chmod = Du = rwx, Dgo = rx, Fu = rw, Fgo = r --delete --stats --log-file = ~ / backup / rsync -dobre + "% F-% I% p "'.log --exclude-from' ~ / exclude.txt '- link-dest = / home / geek2 / files /' cat ~ / backup / time2.txt '-e' ssh -p 12345 '/ home / geek / files / [email protected]: / home / geek2 / files / "date +"% F-% I% p "'/
# nie zapomnij scp pliku dziennika i umieścić go z kopii zapasowej
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / files / "cat ~ / backup / time.txt" / rsync-'cat ~ / backup / time.txt'.log
Byłby to typowy skrypt rsync z migawką. Na wypadek, gdybyśmy gdzieś cię zgubili, rozłóżmy to kawałek po kawałku:
Pierwsza linia naszego skryptu kopiuje zawartość time.txt do time2.txt. Tak potok ma potwierdzić, że chcemy nadpisać plik. Następnie bierzemy aktualny czas i umieszczamy go w time.txt. Pliki te przydadzą się później.
Następny wiersz tworzy plik dziennika rsync, nazywając go rsync-date.log (gdzie data jest faktyczną datą i godziną).
Teraz złożone polecenie rsync, o którym ostrzegaliśmy:
-avzhPR, -e, --delete, --stats, --log-file, --exclude-from, --link-dest - Tylko przełączniki, o których mówiliśmy wcześniej; przewiń w górę, jeśli potrzebujesz przypomnienia.
--chmod = Du = rwx, Dgo = rx, Fu = rw, Fgo = r - Są to uprawnienia do katalogu docelowego. Ponieważ robimy ten katalog w środku naszego skryptu rsync, musimy określić uprawnienia, aby nasz użytkownik mógł zapisywać do niego pliki.
Używanie poleceń daty i kota
Przejdziemy przez każde użycie poleceń date i cat wewnątrz polecenia rsync, w kolejności, w jakiej występują. Uwaga: zdajemy sobie sprawę, że istnieją inne sposoby na wykonanie tej funkcji, szczególnie przy użyciu zmiennych deklarujących, ale do celów tego przewodnika postanowiliśmy użyć tej metody.
Plik dziennika jest określony jako:
~ / backup / rsync-seekate + "% F-% I% p" '. log
Alternatywnie mogliśmy określić to jako:
~ / backup / rsync-'cat ~ / backup / time.txt'.log
Tak czy inaczej, --plik dziennika Polecenie powinno być w stanie znaleźć wcześniej utworzony datowany plik dziennika i zapisać do niego.
Plik docelowy łącza jest określony jako:
--link-dest = / home / geek2 / files / 'cat ~ / backup / time2.txt'
Oznacza to, że --link-dest komenda otrzymuje katalog poprzedniej kopii zapasowej. Jeśli uruchamiamy kopie zapasowe co dwie godziny, a jest godzina 16:00, kiedy uruchomiliśmy ten skrypt, a następnie --link-dest Polecenie szuka katalogu utworzonego o 14:00 i przenosi tylko te dane, które zostały zmienione od tego czasu (jeśli istnieją).
Powtarzam, dlatego plik time.txt jest kopiowany do time2.txt na początku skryptu, więc --link-dest polecenie może odwoływać się do tego później.
Katalog docelowy jest określony jako:
[email protected]: / home / geek2 / files / "date +"% F-% I% p "'
To polecenie po prostu umieszcza pliki źródłowe w katalogu, który ma tytuł bieżącej daty i godziny.
Na koniec upewniamy się, że kopia pliku dziennika jest umieszczona wewnątrz kopii zapasowej.
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / files / "cat ~ / backup / time.txt" / rsync-'cat ~ / backup / time.txt'.log
Używamy bezpiecznej kopii na porcie 12345, aby pobrać dziennik rsync i umieścić go w odpowiednim katalogu. Aby wybrać poprawny plik dziennika i upewnić się, że trafia on we właściwym miejscu, plik time.txt musi zostać odwołany za pomocą komendy cat. Jeśli zastanawiasz się, dlaczego zdecydowaliśmy się na cat time.txt zamiast po prostu użyć polecenia date, to dlatego, że podczas uruchamiania komendy rsync mogło upłynąć dużo czasu, więc aby mieć pewność, że mamy odpowiedni czas, po prostu szukamy kota. dokument tekstowy, który stworzyliśmy wcześniej.
Automatyzacja
Użyj Crona na Linuksie lub Harmonogramu zadań w Windows, aby zautomatyzować skrypt rsync. Jedną rzeczą, na którą musisz uważać, jest upewnienie się, że kończysz wszystkie aktualnie uruchomione procesy rsync przed kontynuowaniem nowego. Harmonogram zadań wydaje się automatycznie zamykać wszystkie działające instancje, ale w przypadku Linuksa musisz być trochę bardziej kreatywny.
Większość dystrybucji Linuksa może korzystać z polecenia pkill, więc pamiętaj o dodaniu następujących elementów na początku skryptu rsync:
pkill -9 rsync
Szyfrowanie
Nie, jeszcze nie skończyliśmy. W końcu mamy fantastyczne (i darmowe!) Rozwiązanie do tworzenia kopii zapasowych, ale wszystkie nasze pliki są nadal podatne na kradzież. Mam nadzieję, że tworzysz kopie zapasowe swoich plików w miejscu odległym o setki mil. Bez względu na to, jak bezpieczne jest to odległe miejsce, kradzież i hakowanie zawsze mogą być problemami.
W naszych przykładach tunelowaliśmy cały ruch rsync przez SSH, co oznacza, że wszystkie nasze pliki są szyfrowane podczas przesyłania do miejsca docelowego. Musimy jednak upewnić się, że miejsce docelowe jest równie bezpieczne. Pamiętaj, że rsync szyfruje twoje dane tylko podczas ich przesyłania, ale pliki są szeroko otwarte po dotarciu do celu.
Jedną z najlepszych funkcji rsync jest to, że przesyła ona tylko zmiany w każdym pliku. Jeśli wszystkie twoje pliki są zaszyfrowane i dokonają jednej drobnej zmiany, cały plik będzie musiał zostać ponownie przesłany w wyniku szyfrowania, które całkowicie losuje wszystkie dane po każdej zmianie.
Z tego powodu najlepiej / najłatwiej jest użyć pewnego rodzaju szyfrowania dysku, takiego jak BitLocker dla Windows lub dm-crypt dla systemu Linux. W ten sposób twoje dane są chronione w przypadku kradzieży, ale pliki mogą być przesyłane za pomocą rsync, a twoje szyfrowanie nie przeszkadza w jego działaniu. Dostępne są inne opcje działające podobnie do rsync lub nawet implementujące jakąś formę, takie jak Duplikacja, ale brakuje im niektórych funkcji, które ma do zaoferowania rsync.
Po skonfigurowaniu kopii zapasowych migawek w lokalizacji poza siedzibą i zaszyfrowaniu źródłowych i docelowych dysków twardych, proszę poklepać się za opanowanie rsync i wdrożenie najbardziej niezawodnego rozwiązania do tworzenia kopii zapasowych danych.